

We Built a Multi-Cloud ETL Demo Before We Won the Work
(Remember when I said I’d do this monthly? Me neither.)
Some time ago, we were approached by a potential partner about an upcoming RFP. After a few rounds of interviews and deep dives, we were excited to get the green light to help them respond. The project sounded right up our alley: take a bunch of data sources, pull them into BigQuery, and do it all in a clean, scalable, automated way.
Once we dug into the RFP—fifty pages of classic enterprise jargon—we knew we didn’t just want to talk about our capabilities, we wanted to show them. So instead of tossing in a diagram and calling it a day, we built a working demo: a multi-cloud ETL pipeline that pulled data from Azure SQL, staged it in GCS, and loaded it into BigQuery using Cloud Run jobs, Terraform, and CI/CD.
It came together fast, worked exactly as intended, and reminded us why we love this work—give us a problem and a cloud account, and we’ll build something useful. This post walks through what we built and how we’d take it further. If your team is facing similar challenges, we’d love to help.
What We Built
A GCP Artifact Registry for storing Docker images
An Azure SQL Database as the source system, with firewall rules configured for access from GCP
A Google Cloud Storage bucket for intermediate CSV file storage
A BigQuery dataset and table as the final data destination
Cloud Run (v2) jobs to handle both extract and load operations
Terraform to provision all infrastructure
CI/CD automation using GitHub Actions to deploy infrastructure and application code

A 5 minute drawing laying out the architecture. (Side note, we ended up not using EventArc, but we would in a production environment)
ETL Flow Breakdown
Here’s how the data flows through the system:
Extract: A Python job running in Cloud Run connects to the Azure SQL DB, runs a query, and writes the results as a CSV file to a GCS bucket.
Load: When the file lands in GCS, an EventArc trigger fires another Cloud Run job that loads the CSV from GCS into a BigQuery table.
Automate: CI/CD and Terraform manage all provisioning and deployment tasks end to end.
We created Python scripts to handle the extraction step of our ETL pipeline. It connects to the Azure SQL database, pulls the data into a pandas DataFrame, and writes it to Google Cloud Storage as a CSV file. The script itself is baked into a Docker image and pushed to Artifact Registry on GCP, where it's used as the container for our Cloud Run job.
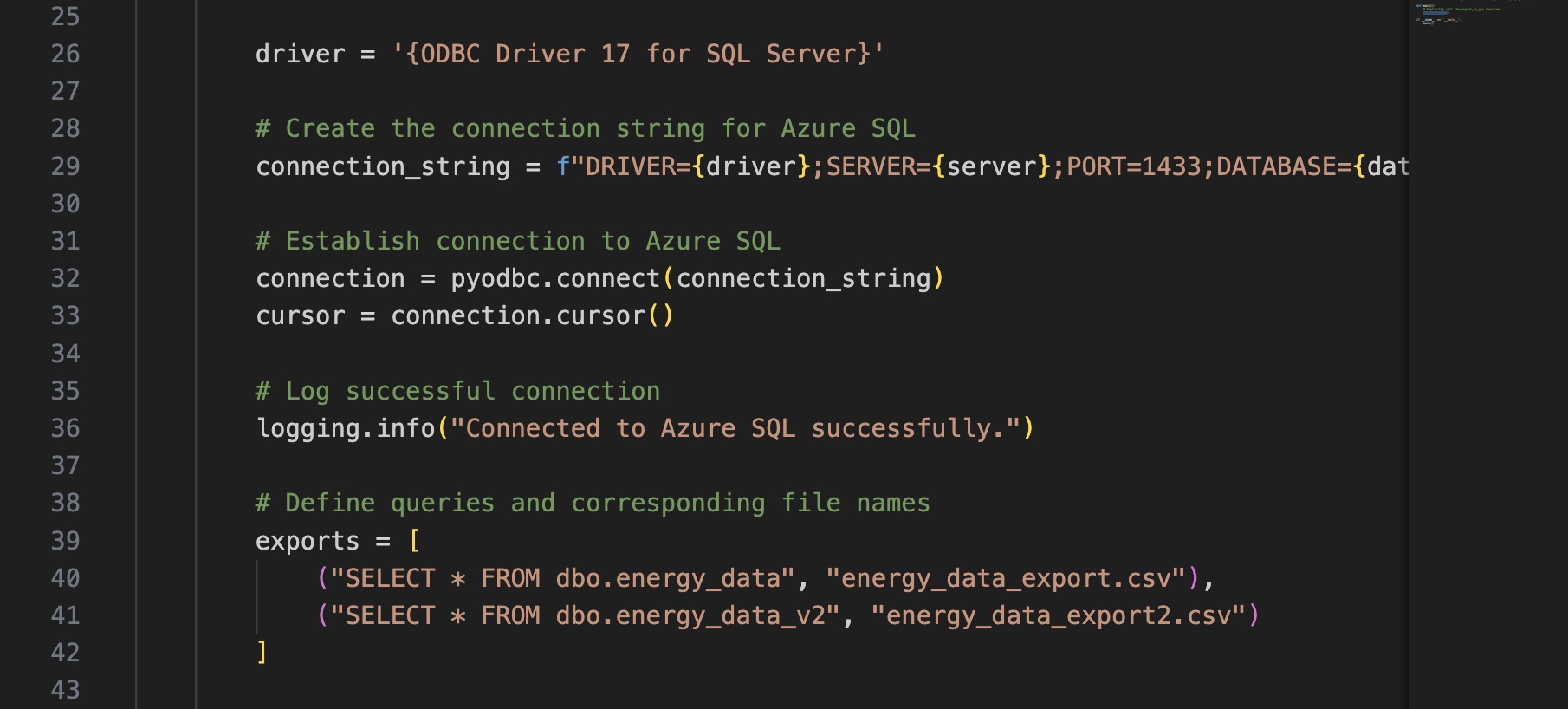
Pulling from SQL.
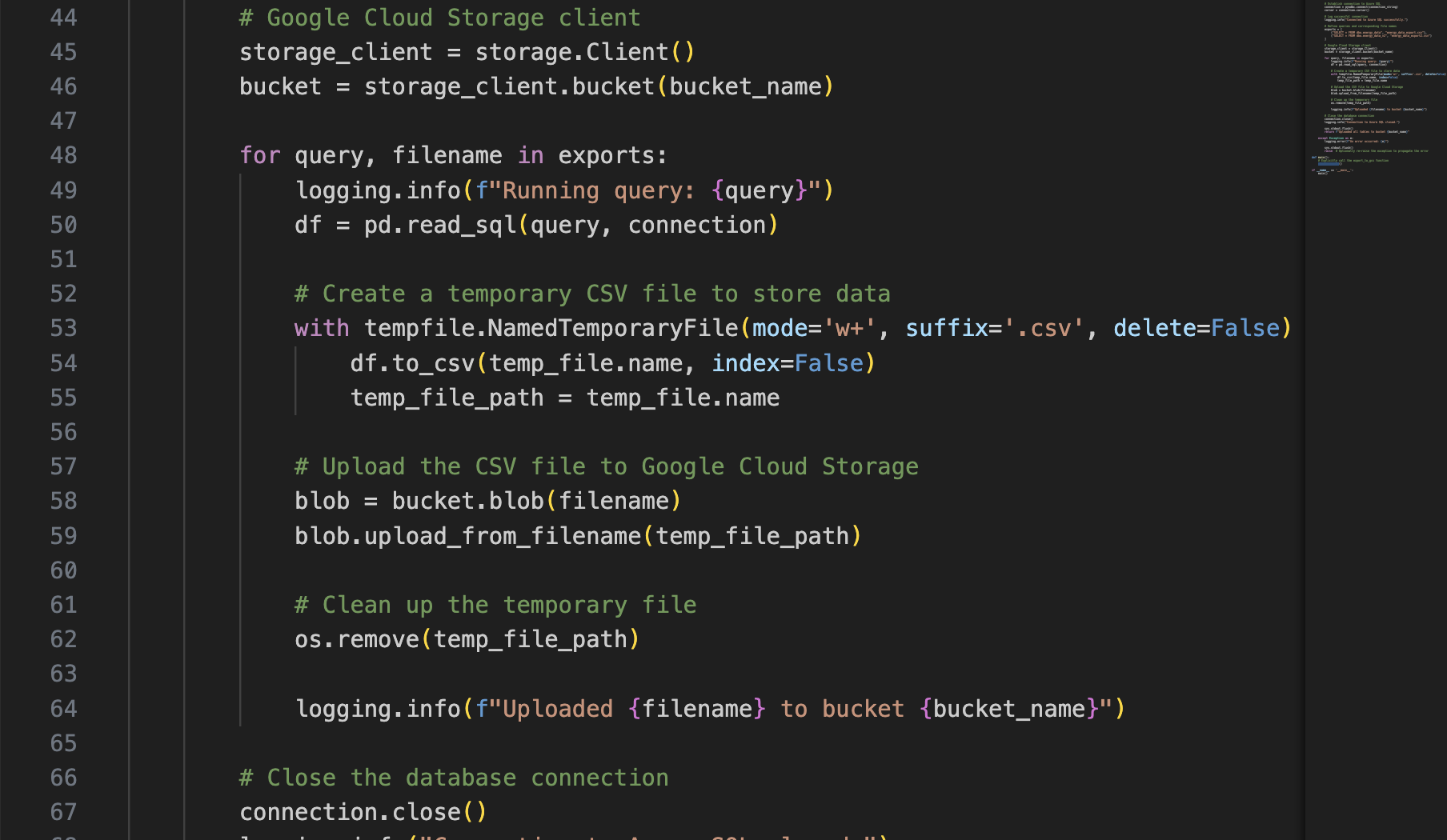
Uploading data to GCS as a CSV.
This second script takes the raw file from the GCS bucket and loads it into table in BigQuery.
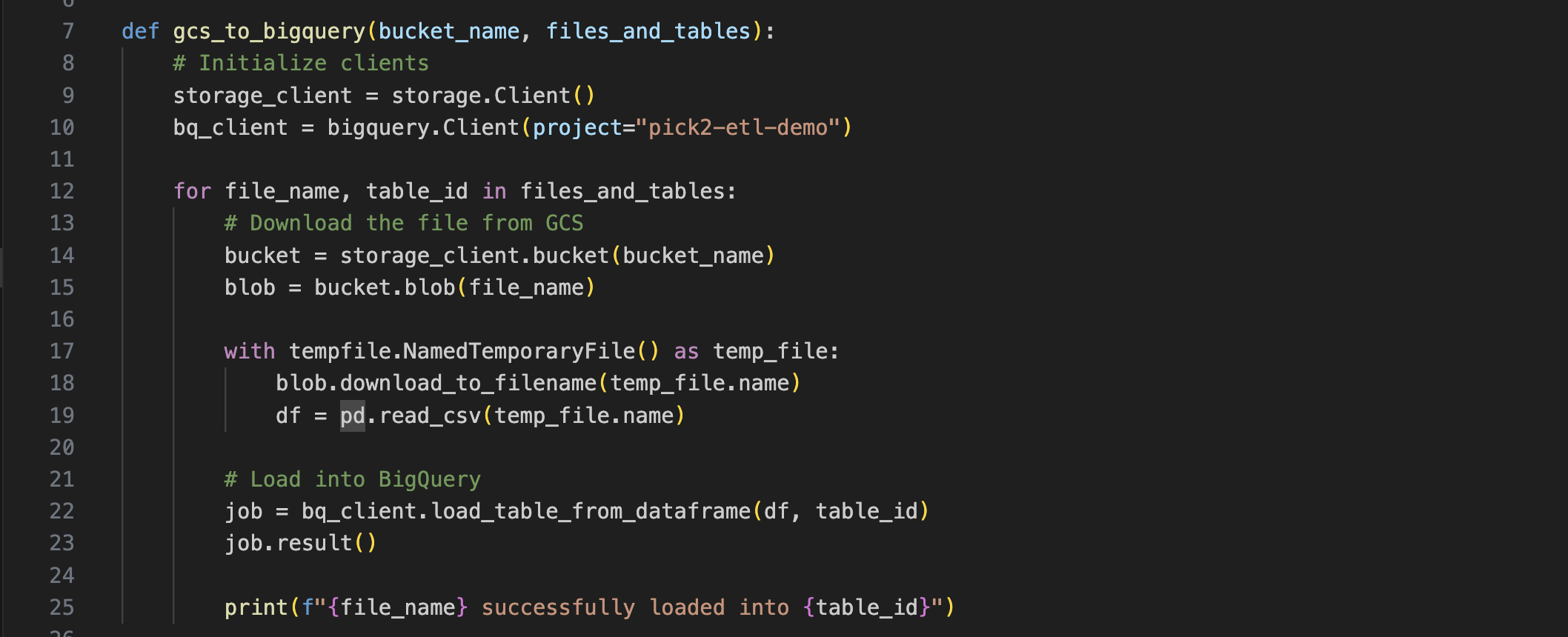
Loading into BQ with a little help from the BQ Library.
A Little IAC
We love Terraform because it keeps things simple, repeatable, and boring—in the best way possible. No clicking around in the console, no wondering what changed between environments. As you see below, it doesn’t take a lot of lines to tell GCP to spin up the Cloud Run jobs. We leveraged Terraform for all of the cloud resources in Azure and GCP — if you want to see all of it, feel free to check out our repo.
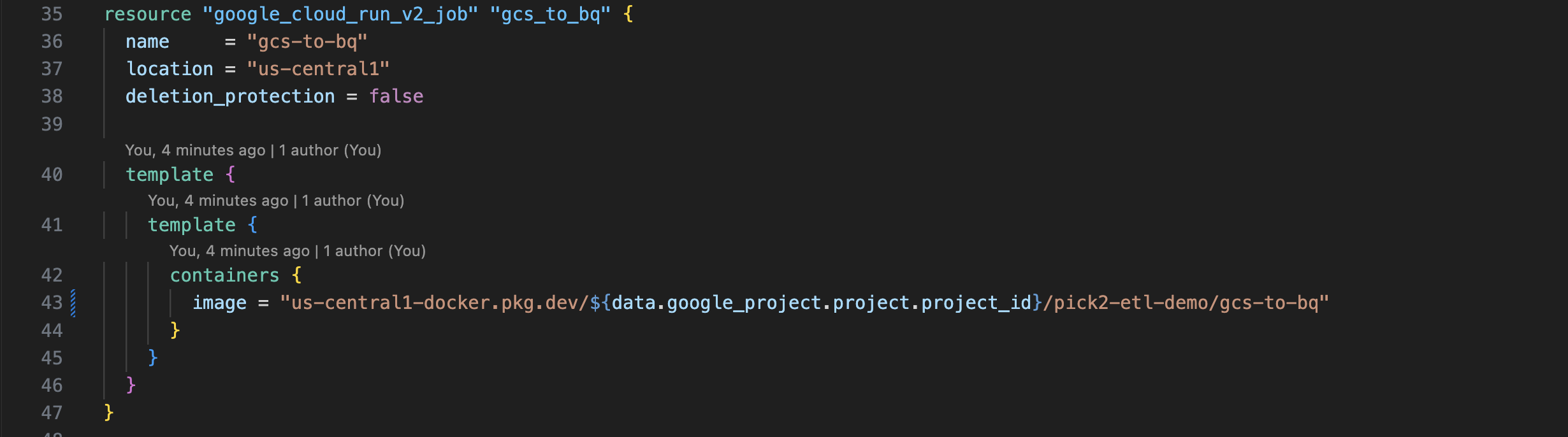
A CloudRun job in 12 lines.
Github Actions For CI/CD
We’ve been playing around with a few different CI/CD platforms lately—GitLab, Azure Pipelines, and BitBucket. But GitHub will always have a soft spot in our hearts, especially when we need to get something up and running fast. It’s straightforward, well-documented, and just works when you need it to. Here’s a snapshot of the steps:

A Github Action for the Artifact Registry

A Github Action pushing our Docker images to the Registry.

The ETL Infrastructure in Azure and GCP.
Receipts
Let’s take a look at how it all comes together. Below are a few screenshots that show the full flow in action—from the source data in Azure SQL, to the Cloud Run jobs, to the files landing in GCS, and finally the data loaded into BigQuery. A clear view of each step across both clouds.
First, a look at the data in Azure:

Fake data in Azure.
Next, CloudRun Job 1 of 2. This one pulls the data from the Azure SQL DB and sticks it into a GCS bucket.

Cloud Run Job in GCP bringing data over.

CSV files in GCS.
Finally, we run CloudRun Job #2 to load the data into BigQuery.

Cloud Run Job #2.

Final Thoughts
What started as a technical proof of concept for an RFP turned into a reusable, cloud-native pattern for multi-cloud ETL. With a small set of services—Azure SQL, GCS, Cloud Run, and BigQuery—we were able to deliver a clean, scalable architecture that can serve as the foundation for more advanced data processing pipelines.
We’ll keep refining and extending this pattern in future projects, but if your team is wrestling with similar challenges—moving data between clouds, wrangling infrastructure, or just trying to get something shipped—we’d love to help.